




Introduction
Hello, 1337 h4xxors, I recently started the Certified Bug Bounty Hunter course from HackTheBox for a simple reason: I'm lame at Web Hacking 🫥
This has made me want to write more blog posts about what I've learned. This will also help me address one of my main drawbacks. I'm TOO perfectionist; I always try to do my best, with too many expectations and this stops me from creating a lot of content.
In this blog post, I will talk about the HTTP protocol at a high level. Here we go.
A Piece Of History
Let's go back to the late 80's with Tim Berners-Lee. Tim is a computer scientist who revolutionized the Internet through his work. At this time, he got a job as a contractor at CERN (European Organization for Nuclear Research) the world's largest particle physics laboratory in the world based in Geneva, Swiss.
At this time CERN was the largest Internet node in Europe. Tim saw a big opportunity to combine multiple technologies to create something unique.
He tried to solve a problem linked to the management and sharing of information within CERN and, more broadly, within the global scientific community.

I just had to take the hypertext idea and connect it to the TCP and DNS ideas and—ta-da!—the World Wide Web.
— Tim Berners-Lee
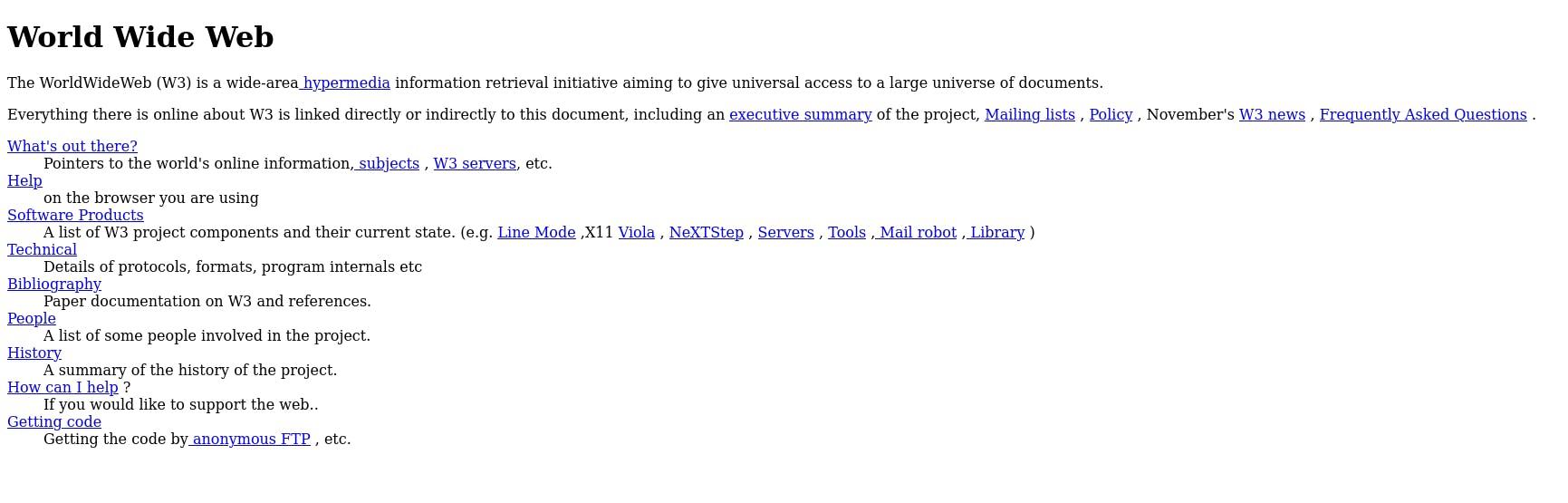
This is the first website, you can see it: here
Indeed, that's what Tim did. He took three main components :
The hypertext idea: He created the HTML language extended from the SGML language
TCP: To facilitate the sharing of web pages between networks
DNS: To link the IP address of a web server to a domain name
He also developed a browser called "WorldWideWeb" and a web server.

You can try this browser: here.
The HTTP Protocol: How Does It Work
Now in 2023, most applications (mobile and web) interact with the Internet and many of these communications are conducted through the HyperText Transfert Protocol.
For an HTTP communication, you need two things; a client and a server :
The client "asks" for some resources from the web server, this is called an HTTP request. What types of resources does the client ask for? Files (HTML files, CSS files, Javascript files etc.). An HTTP request can take several forms. This is the HTTP Method (e.g. HTTP Get, to request a web page)
The web server answers these requests by sending (or not) the resources asked by the client. This is an HTTP response. HTTP responses are accompanied by what we call an HTTP Status Code (e.g. 200 OK, when the request is a success)
When we talk about a client in this context, you can replace "client" with "browser" if this can make this easier to understand.
By default, communications with web servers are made via ports 80 (for the HTTP protocol) and 443 (for the HTTPS protocol). However, this can be changed depending on the web server configuration.
URL and FQDN
"Yeah that's cool but how does the web browser know which server it should reach ?"
To do so, you need to specify a FQDN (Full Qualified Domain Name) as a URL (Uniform Resource Locator) to reach the desired website. To understand the differences, you need to understand the components of both these.
The FQDN
The FQDN is used by DNS servers to perform the "translation" domain names -> IP addresses. It typically appears as follows: example.com
An FQDN is configurated like this :

The URL
"If example.com is an FQDN, what the heck is a URL then ?"
The Uniform Resource Locator is used by web browsers to navigate to specific web pages. A URL provides many more specifications than a FQDN :

Resources via HTTP are accessed via a URL, which involves more than just typing the website's name.
Description Of Each URL Component
| Component | Example | Description |
| Scheme | http:// https:// | Identifies the protocol used |
| User info | admin:password@ | Option containing creds (separated by a colon) for authentication, separated from the host by @ |
| Host | website.com | Resource location can be a hostname or an IP address |
| Port | :80 | The port is separated from the host by a colon and set to 80 (HTTP) by default and 443 (HTTPS) |
| Path | /dashboard.php | Points to the desired resource (file or folder). If nothing is specified, the server returns the default index (e.g. index.html) |
| Query String | ?login=true | Starts with a "?" followed by a parameter (e.g. login) and a value (e.g. true). Several parameters can be separated by an ampersand (&) |
| Fragments | #status | Fragments are processed by the client-side browser to locate sections within the main resource (e.g. a header or a specific section on the page) |
Not all URL components are required to access a resource. The main parts are the Scheme and the Host. Otherwise, the request would have no resource to fetch.
{kind=link}
HTTP Flow
What if Bob wants to access a website?
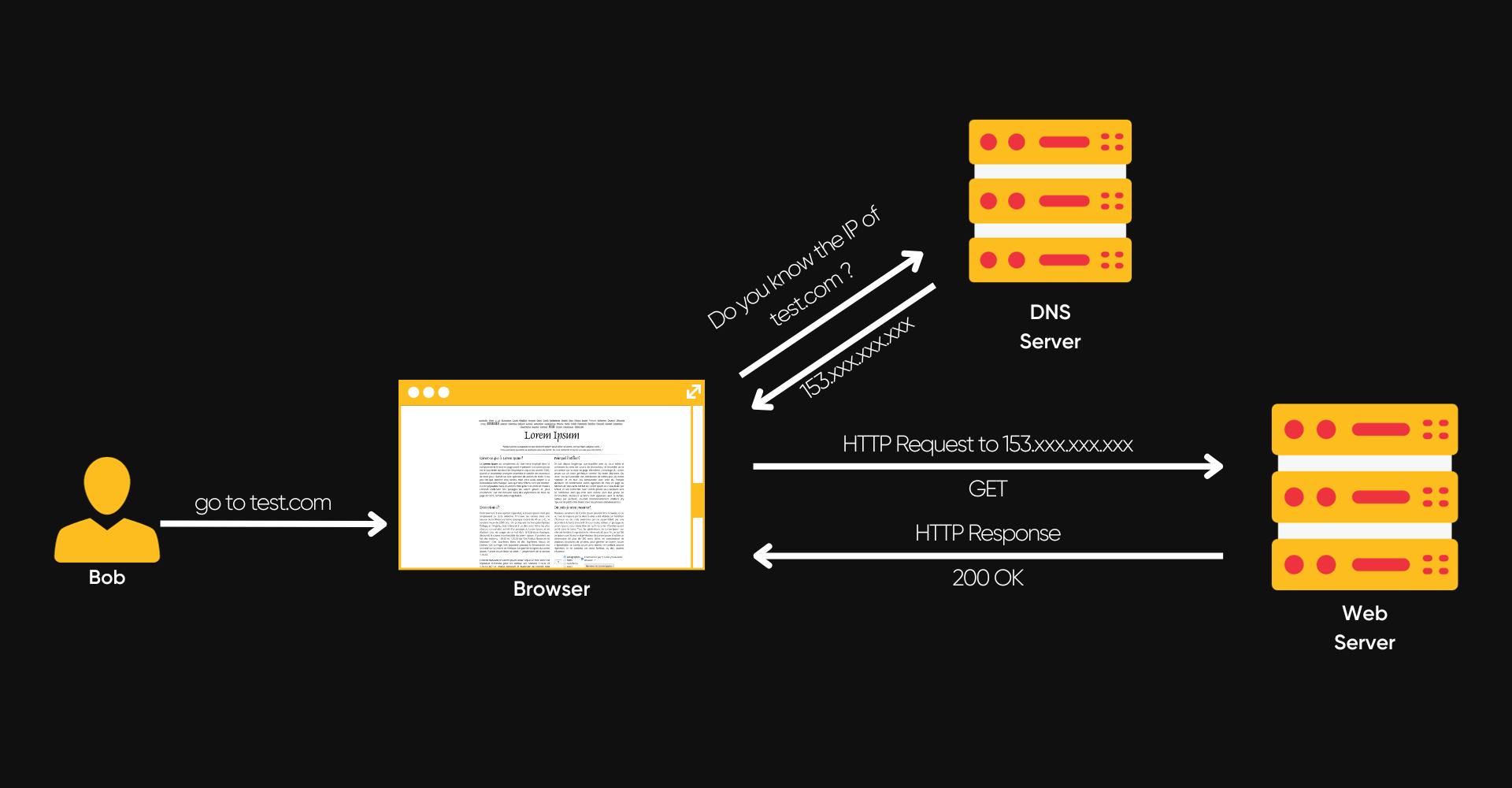
1. Bob enters a URL
test.com.2. The browser looks at the local file
/etc/hosts(Linux) orC:\Windows\System32\drivers\etc\hosts(Windows). If the requested domain is already located in this file, the browser will send a request directly to the web server, otherwise, it will contact a DNS server.3. The DNS server looks up the IP address of the web server for the
test.comdomain.4. The DNS server returns the web server's IP address to Bob's browser
5. Bob's browser sends a GET request on port 80 (HTTP) asking for the root folder of the web server
/, by default web servers are configured to return a/index.htmlpage when the root folder/is requested by a client6. The server sends Bob the
/index.htmlfile, along with a200 OKresponse code indicating that the request has been successfully processed.7. Finally, the browser displays the page for Bob.
This is an explanation of a very basic request.
Outro
"Hey, you talked about HTTP but what about HTTPS ? 🤨"
HTTPS is a little bit different, just a little 🤏. This will be the topic of the next blog post.
Until then hit the subscribe button on Instagram: h0neyp0t.sec
Don't settle for null, strive for #0...
h0neyp0t.